




글 목록
- 데이터 플랫폼 구축기 Part 1 - Lakehouse 기반 데이터 플랫폼 소개
- 데이터 플랫폼 구축기 Part 2 - 필요한 기능이 없으면 기여하면 되지 않을까요?
- 데이터 플랫폼 구축기 Part 3 - Lakehouse 사용기
배경
원프레딕트는 산업 설비에서 발생하는 물리 현상을 센서를 통해 수집하고, 수집된 데이터에서 정보를 추출해 산업 설비의 상태를 추정하며, 이를 통해 설비의 상태를 예측진단하고 처방할 수 있는 제품을 제공하고 있습니다.
산업 설비의 전류/진동 신호에서 양질의 정보를 추출하기 위해서는 높은 해상도의 데이터 샘플이 필요합니다.
또한 설비의 상태를 예측진단하기 위해서는 시간의 흐름에 따른 데이터의 변화를 추적해야하기 때문에 다루는 데이터의 용량이 제법 커지게 됩니다.
저희가 관리하는 설비가 늘어남에 따라 기존의 데이터 관리 방법으로는 ML 프로세스를 효율적으로 수행하기 어려워졌습니다. 이러한 문제를 해결하기 위해 레이크하우스 기반의 데이터 플랫폼을 구축하기로 결정하였습니다.
아키텍처
현재 생각하고 있는 아키텍처는 다음과 같습니다. 다양한 관점을 한 그림에 표현하느라 조금 복잡해보일 수 있지만, 차근차근 설명해보겠습니다.
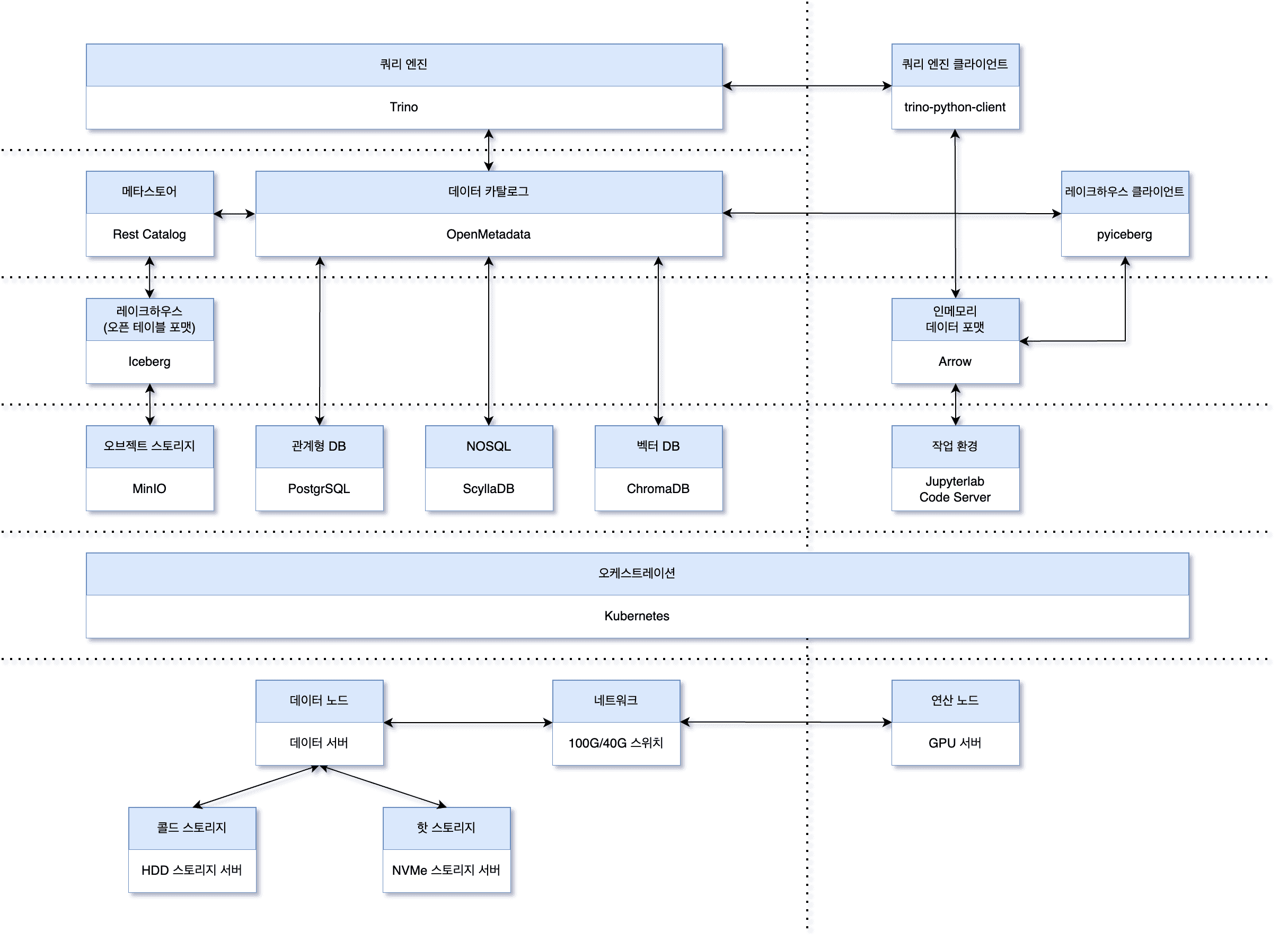
세로의 점선 왼쪽이 데이터 플랫폼이 구축된 노드들을 의미하고, 오른쪽은 사용하는 작업 노드를 의미합니다. 가로의 점선은 논리적으로 구분할 수 있는 계층을 의미합니다.
- 물리 계층: 사내에 데이터 플랫폼을 구축하기로 했기 때문에 이 부분부터 개선을 시작하였습니다. 빠른 데이터 입출력을 위해 기존의 HDD 스토리지 서버 외에 NVMe 스토리지 서버를 새로 도입하였고, 기존의 10G 네트워크도 100G/40G로 증설하였습니다.
- 컨테이너 인프라 계층: 유연한 확장과 관리 용이성을 위해 데이터 서버도 쿠버네티스 클러스터에 포함하기로 하였습니다.
- 스토리지 계층: 오브젝트 스토리지로는 MinIO, 관계형 DB와 NOSQL은 분산 시스템에 적합한 PostgreSQL과 ScyllaDB를 선택하였고, 최근 LLM을 이용하는 프로젝트도 진행되고 있어서 ChromaDB도 선택했습니다.
- 데이터 포맷 계층: Iceberg를 통해 기존의 관리 방식인 데이터 레이크에서 데이터 레이크하우스로 전환하였습니다.
- 카탈로그 계층: Iceberg의 카탈로그인 REST 카탈로그와 이를 포함한 모든 스토리지의 메타데이터를 관리하는 OpenMetadata를 선택하였습니다.
- 쿼리 엔진 계층: 더욱 빠른 데이터 조회 속도를 위한 쿼리엔진으로는 Trino를 선택하였습니다.
Iceberg 선택 이유
기존에는 오브젝트 스토리지에 원시 데이터를, 관계형 데이터베이스에 메타 데이터를 저장하고, 메타 데이터를 통해 오브젝트 스토리지에 저장된 위치를 파악한 뒤 원시 데이터를 조회하는 방식으로 데이터를 관리하고 있었습니다. 이렇게 사용할 경우 원시 데이터 조회가 번거롭고, 메타 데이터와 원시 데이터의 무결성을 보장하기 어려웠습니다.
데이터 포맷도 스트리밍에서 취득되는 데이터 형식 그대로 저장하고 있었습니다. 위에서 말씀드렸다시피 설비의 지속적인 열화를 추적하는 것이 핵심 기능이기 때문에, 이 와 같은 형식으로 데이터를 조회할 경우 디스크 I/O 속도가 매우 느려지게 됩니다.
이를 해소하기 위해 Iceberg를 도입하여 데이터 레이크하우스를 구축하기로 했습니다. 메타 데이터와 원시 데이터를 묶어 스키마를 구성하였고, 스트리밍 환경에서 들어온 데이터를 기간별로 묶어서 파일의 크기를 늘려서 저장하였습니다.
다른 대안으로 Delta Lake도 있었지만, 현재 저희는 Ray를 기반으로 한 분산 시스템을 활용하고 있기 때문에 Spark 엔진과의 연동이 핵심인 Delta Lake의 경우 저희에게는 적합하지 않다고 판단하였습니다.
OpenMetadata 선택 이유
기존에는 각 제품/프로젝트 별로 데이터를 관리했기 때문에 자신이 담당하는 데이터 외에는 다른 데이터에 대한 정보를 알기 어려웠습니다. 이를 해소하기 위해 OpenMetadata를 도입하여 사내의 모든 데이터에 대한 접근성을 높였습니다.
OpenMetadata는 데이터의 메타데이터를 관리하는 것 뿐만 아니라, 데이터의 리니지를 추적하고, 데이터의 소유자를 관리하는 등 다양한 기능을 제공합니다. 이를 통해 데이터의 품질을 높이고, 데이터의 소유자를 추적함으로써 데이터의 보안성을 높일 수 있었습니다.
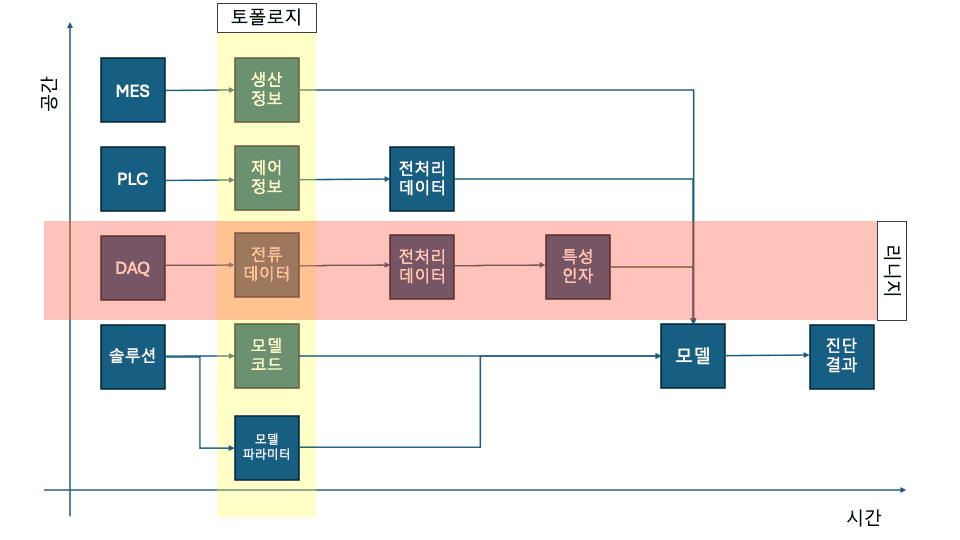
또한 산업 데이터의 경우 데이터의 시간적인 흐름인 리니지도 중요하지만, 다른 데이터 원천에서 수집되지만 함께 봐야하는 경우가 있습니다. 저희는 이러한 공간적인 관계를 데이터 토폴로지라고 정의하고 리니지와 토폴로지를 묶어서 데이터 매트릭스라고 정의하였습니다. 데이터 매트릭스 역시 OpenMetadata의 기능을 통해 관리하려 합니다.
Trino 선택 이유
위에서 말씀드린 것처럼 저희 제품은 시간의 흐름에 따라 산업 자산의 상태를 추정하고, 이를 통해 예측진단하고 처방하는 것이 핵심 기능입니다. 따라서 새로운 모델을 개발하고 검증하는 배치 프로세스 과정에서 많은 양의 데이터를 조회해야 합니다. 이 때 더욱 빠른 프로세스를 위해 Trino를 도입하였습니다.
앞으로 해야할 일
위에 말씀드린 내용 중 개념상으로만 존재하는 것도 있고, 구축되어서 테스트하고 있는 것들도 있습니다. 최종적으로 사내 런칭을 2024년 상반기 내에 하는 것이 목표입니다. 데이터 플랫폼에 대한 포스팅은 한동안 구축 과정에서 발생한 다양한 이슈와 이를 해결한 과정을 공유하려 합니다. 이를 통해 데이터 플랫폼 구축에 관심이 있는 분들에게 도움이 되었으면 좋겠습니다. 런칭 후에는 운영 과정에서 발생하는 다양한 이슈에 대해서 공유해 드리겠습니다.
MLOps 팀에서는 저희와 함께 MLOps 플랫폼, 데이터 플랫폼을 개발하실 분들을 찾고 있습니다. 관심이 있으시다면 언제든지 연락해 주세요. 꼭 입사 지원이 아니더라도 커피 챗 등을 통해 ML 프로세스를 지원하는 플랫폼 개발에 대해 이야기 나누는 것도 좋습니다.