




글 목록
- 데이터 플랫폼 구축기 Part 1 - Lakehouse 기반 데이터 플랫폼 소개
- 데이터 플랫폼 구축기 Part 2 - 필요한 기능이 없으면 기여하면 되지 않을까요?
- 데이터 플랫폼 구축기 Part 3 - Lakehouse 사용기
어떻게 데이터 로드 속도를 빠르게 할까?
이전에 말씀드린 것처럼, DAQ에서 획득한 신호의 원시 데이터는 데이터 저장소에 저장됩니다. 원시 데이터는 각 채널당 수십만 개의 요소를 가진 여러 채널의 긴 배열 형태로, 운영/설비 정보(메타데이터)와 함께 수집 주기마다 수집되어 작은 파일(약 1MB)로 메타데이터(RDB)와 오브젝트 스토리지에 저장됩니다.
데이터를 불러오기 위해서는 RDB에서 메타데이터를 쿼리하고, 오브젝트 스토리지에서 파일을 로드하는 두 단계를 거쳐야 합니다. 이 과정에서 여러 작은 파일을 반복해서 읽어야 하므로 잦은 I/O 오버헤드로 인해 낮은 처리량(Small Files Problem)이 발생합니다. 이러한 문제는 빅 데이터 시스템에서 공통으로 발생합니다.
여기서 과제는 사용성을 위해 데이터를 수집 주기 단위로 저장하면서도, 로드 시에는 I/O 오버헤드를 줄여 큰 파일처럼 불러올 수 있는 방법을 찾는 것이었습니다. 즉, 작은 파일 단위로 저장하되, 로드 시에는 큰 파일처럼 불러와 속도를 향상하고자 했습니다. 이를 위해 작은 파일을 큰 파일로 불러오는 중간 미들웨어를 갖춘 시스템을 찾기 시작했습니다.
또한, 시스템 구축과 관리가 용이하며 증가하는 데이터를 지속적으로 관리할 수 있게 스케일 아웃이 가능해야 하고, 사용자가 직관적으로 쉽게 사용할 수 있는 편의성도 고려해야 했습니다.
Lakehouse는 왜 빠를까?
레이크하우스는 데이터 웨어하우스의 장점과 데이터 레이크의 장점을 결합하여 ACID 연산과 정형/비정형 데이터 형태와 볼륨에 관계없이 데이터들을 저장/관리할 수 있다는 이점 등을 지니는데 여기에서는 이러한 기능 외에 속도 측면을 집중하여 알아보려고 합니다.
Lakehouse Concept
우선, 레이크하우스의 개념을 잠시 살펴보자면 2021년 처음 데이터 레이크하우스 개념을 소개한 저자들(Armbrust, Ghodsi, Xin, and Zaharia)에 따르면 a data management system based upon low-cost and directly accessible storage that also provides analytics DBMS management and performance features such as ACID transactions, data versioning, auditing, indexing, caching and query optimization 라고 합니다.
Iceberg, Hudi, Delta Lake과 같은 레이크하우스 제품들은 일반적으로 Parquet와 같은 High-Performance 포멧으로 파일들을 저장하되 ACID 연산을 가능하게하고 레코드 단위의 연산, 인덱싱, 메타데이터 관리, Scalability 등의 특징들을 갖으며 이를 지원하기 위해 아래와 같은 레이어로 구성되어 동작합니다.
Lakehouse Layers
레이크하우스는 제품별로 약간의 차이가 있을 수 있지만 일반적인 컨셉의 레이어는 아래 그림과 같습니다.
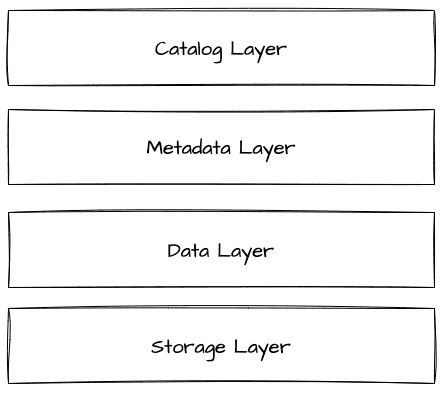
스토리지는 Minio와 같은 오브젝트 스토리지를 사용하여 실제 물리적 데이터를 저장하는 공간입니다. 여기에는 Parquet와 같은 파일 포맷으로 실제 데이터(DataFiles)를 저장합니다. DataFiles는 메타데이터에 의해 기록되고 관리되며, 일부 레이크하우스 제품에서는 로그를 사용하여 데이터 히스토리 정보를 관리합니다. 이러한 메타데이터를 통해 데이터 파일의 위치, 데이터 스키마, 파티션, 버전 관리, 스냅샷, ACID, 타임 트래블(Time Travel) 기능을 지원합니다.
메타데이터가 중요한 이유는 쿼리 계획을 세우고 이를 통해 병렬 연산을 수행하여 데이터 로드 속도를 빠르게 하기 때문입니다. API를 이용해 데이터를 로드할 때, 멀티프로세싱을 수행하여 메타데이터를 통해 데이터를 병렬적으로 파악하고 불러옵니다.
Storage Layer는 실제 데이터가 저장되는 물리적 저장소로, HDFS, Amazon S3, Azure Storage, Google Cloud Storage, Minio 등과 같이 확장 가능하고 저비용의 저장소로 구성됩니다. Data Layer는 실제 테이블 데이터를 의미하며, Storage Layer의 물리적 저장소에 Parquet(기본값), ORC, Avro와 같은 형식의 파일로 저장됩니다. 이는 작업 부하에 적합한 형식으로 지정하여 저장됩니다. 예를 들어, Parquet는 컬럼형 구조로 하나의 파일을 병렬 연산으로 로드할 수 있어 높은 성능을 요구하는 OLAP 작업 부하에 적합합니다. Metadata Layer는 테이블에 대한 모든 메타데이터를 관리하는 레이어입니다. 트리 구조 형태로 데이터를 추적하며, 대규모 데이터셋, 타임 트래블, 스키마 진화를 가능하게 합니다. Catalog Layer는 테이블을 읽고 쓸 때 데이터 위치를 빠르게 찾아주는 역할을 합니다. 또한 테이블의 스키마와 일부 메타정보를 확인할 수 있으며, Iceberg에서는 카탈로그가 메타데이터 정보를 확인해 실제 물리적 데이터 위치를 파악합니다.
이와 같은 레이어들로 구성된 레이크하우스는 높은 성능의 테이블 읽기/쓰기를 지원합니다.
Deep Dive into Lakehouse(Iceberg)
저희는 레이크하우스 제품 중 Apache Iceberg를 채택하여 사용하고 있습니다. 여러 제품 중 Iceberg를 선택하게 된 주요 이유는 Data Processing Engine(spark)과 비교적 커플링이 덜해 유연하게 사용할 수 있다는 점이었습니다. 구체적으로는 spark 없이 파이썬 라이브러리(pyiceberg)로만 상대적으로 수월하게 사용 가능하다는 점이었는데요. 다만 파이썬 라이브러리로 사용할 경우 현재로써는 spark보다 지원하는 기능이 상대적으로 적습니다.
Iceberg는 아래와 같은 컴포넌트로 구성됩니다.
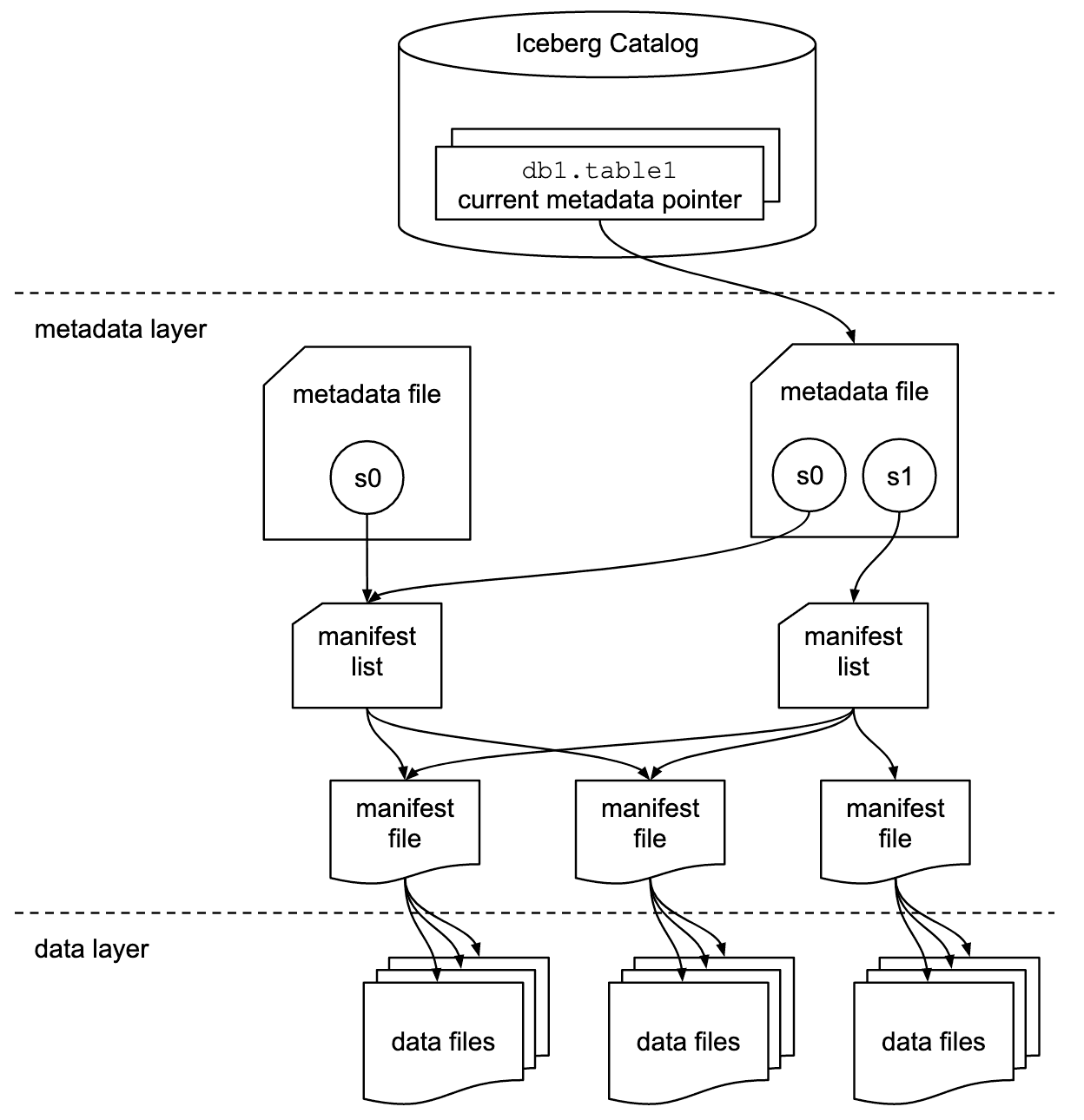 apache Iceberg 구조
apache Iceberg 구조
위에 레이크하우스 Layers에서 언급한 것처럼 catalog, metadata, data layer으로 나누어져 있습니다.
카탈로그는 최신의 메타데이터로 메타 정보들을 읽어와 실제적인 데이터들의 위치를 확인합니다. Iceberg는 metadata와 manifest 파일로 정보들을 관리합니다. 테이블에 쓰기 연산이 발생할 때마다 새로운 메타데이터 파일이 생성되며 최신 메타데이터로 지정합니다. 이러한 형태로 히스토리를 보장하며 versioning, time travel 등의 기능을 지원합니다. 아래는 샘플로 만든 테이블의 metadata.json 정보입니다. 스토리지는 Minio를 사용하여 warehouse 버킷에 저장되어 네임스페이스 / 테이블 / 메타데이터, 데이터와 같은 계층구조로 저장됩니다. 현재는 데이터를 저장한 것 없이 테이블만 만든 상태라 데이터 파일이 존재하지 않습니다.
아래에서 보다시피 메타데이터 정보에는 스키마와 테이블 관련 정보 및 실제 물리적인 저장위치등을 포함하고 있습니다. 이 메타데이터는 데이터 삽입 전의 상태로 첫번째 snapshot입니다. 아래의 메타데이터는 데이터 삽입 후의 상태로 두번째 snapshot이 되어 메타데이터는 snapshot 정보를 관리하게 되어 time-travel과 같은 기능을 지원하게 됩니다.
- 00000-dd6b1201-4c9c-48d8-a76f-0351f705e530.metadata.json(snapshot0)
{
"format-version" : 2,
"table-uuid" : "151947dc-770d-457a-82a2-07e4a36932a2",
"location" : "s3a://warehouse/test_ns/test_data",
"last-sequence-number" : 0,
"last-updated-ms" : 1716797335063,
"last-column-id" : 7,
"current-schema-id" : 0,
"schemas" : [ {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "date_time",
"required" : false,
"type" : "timestamptz"
}, {
"id" : 2,
"name" : "int_data",
"required" : false,
"type" : "long"
}, {
"id" : 3,
"name" : "str_data",
"required" : false,
"type" : "string"
}, {
"id" : 4,
"name" : "map_data",
"required" : false,
"type" : {
"type" : "map",
"key-id" : 6,
"key" : "string",
"value-id" : 7,
"value" : "string",
"value-required" : false
}
}, {
"id" : 5,
"name" : "binary_data",
"required" : false,
"type" : "binary"
} ]
} ],
"default-spec-id" : 0,
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ ]
} ],
"last-partition-id" : 999,
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
"properties" : {
"write.parquet.compression-codec" : "zstd"
},
"current-snapshot-id" : -1,
"refs" : { },
"snapshots" : [ ],
"statistics" : [ ],
"snapshot-log" : [ ],
"metadata-log" : [ ]
}테이블에 데이터를 쓸 때는 우선 최신 메타데이터 정보를 확인하여 테이블 스키마와 파티션 스키마를 검토합니다. 그런 다음 데이터를 Parquet 같은 파일 포맷으로 변환하고 관련 메타데이터를 기록합니다. 이후 manifest 파일을 생성하여 물리적 위치와 기타 통계 정보를 기록합니다. 이러한 정보를 바탕으로 쿼리 시 파일을 선별하여 성능을 향상시킵니다. manifest 파일은 .avro 포맷으로 스토리지에 저장됩니다. 참고로 Iceberg는 두 가지 쓰기 전략을 지원합니다. COW(copy-on-write)는 쓰기 시 새로운 파일을 생성하는 방식이고, MOR(merge-on-read)은 쓰기 시 변경된 부분만 따로 생성하여 읽기 시 병합하는 방식입니다. MOR은 테이블 포맷 버전 2부터 지원합니다.
아래는 실제 아래 샘플 코드의 데이터를 삽입 후에 metadata.json 정보입니다.
- 00001-bf738291-2884-4c28-a441-c41b39af4144.metadata.json(snapshot1)
{
"format-version" : 2,
"table-uuid" : "151947dc-770d-457a-82a2-07e4a36932a2",
"location" : "s3a://warehouse/test_ns/test_data",
"last-sequence-number" : 1,
"last-updated-ms" : 1716803193138,
"last-column-id" : 7,
"current-schema-id" : 0,
"schemas" : [ {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "date_time",
"required" : false,
"type" : "timestamptz"
}, {
"id" : 2,
"name" : "int_data",
"required" : false,
"type" : "long"
}, {
"id" : 3,
"name" : "str_data",
"required" : false,
"type" : "string"
}, {
"id" : 4,
"name" : "map_data",
"required" : false,
"type" : {
"type" : "map",
"key-id" : 6,
"key" : "string",
"value-id" : 7,
"value" : "string",
"value-required" : false
}
}, {
"id" : 5,
"name" : "binary_data",
"required" : false,
"type" : "binary"
} ]
} ],
"default-spec-id" : 0,
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ ]
} ],
"last-partition-id" : 999,
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
"properties" : {
"write.parquet.compression-codec" : "zstd"
},
"current-snapshot-id" : 2106886542339613321,
"refs" : {
"main" : {
"snapshot-id" : 2106886542339613321,
"type" : "branch"
}
},
"snapshots" : [ {
"sequence-number" : 1,
"snapshot-id" : 2106886542339613321,
"timestamp-ms" : 1716803193138,
"summary" : {
"operation" : "append",
"added-files-size" : "28638952",
"added-data-files" : "1",
"added-records" : "500",
"total-data-files" : "1",
"total-delete-files" : "0",
"total-records" : "500",
"total-files-size" : "28638952",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "s3a://warehouse/test_ns/test_data/metadata/snap-2106886542339613321-0-994831ec-03f9-496b-8423-2594c55bbca6.avro",
"schema-id" : 0
} ],
"statistics" : [ ],
"snapshot-log" : [ {
"timestamp-ms" : 1716803193138,
"snapshot-id" : 2106886542339613321
} ],
"metadata-log" : [ {
"timestamp-ms" : 1716797335063,
"metadata-file" : "s3a://warehouse/test_ns/test_data/metadata/00000-dd6b1201-4c9c-48d8-a76f-0351f705e530.metadata.json"
} ]
}메타데이터 정보에서 current-snapshot-id 키에 대한 값을 보면 현재 테이블의 최신 스냅샷 정보를 알 수 있고 snapshot-id 정보로 스냅샷 항목에서 이에 해당하는 manifest list가 저장되어 있는 파일(.avro)을 확인 할 수 있습니다.
"current-snapshot-id" : 2106886542339613321{
"sequence-number" : 1,
"snapshot-id" : 2106886542339613321,
"timestamp-ms" : 1716803193138,
"summary" : {
"operation" : "append",
"added-files-size" : "28638952",
"added-data-files" : "1",
"added-records" : "500",
"total-data-files" : "1",
"total-delete-files" : "0",
"total-records" : "500",
"total-files-size" : "28638952",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "s3a://warehouse/test_ns/test_data/metadata/snap-2106886542339613321-0-994831ec-03f9-496b-8423-2594c55bbca6.avro",
"schema-id" : 0
}데이터를 write 했으니 parquet 형태의 datafile 또한 저장됩니다

저장된 manifest list 파일을 들여다보면 manifest file의 위치를 확인 할 수 있습니다.
[
{
"manifest_path": "s3a://warehouse/test_ns/test_data/metadata/994831ec-03f9-496b-8423-2594c55bbca6-m0.avro",
"manifest_length": 4661,
"partition_spec_id": 0,
"content": 0,
"sequence_number": 1,
"min_sequence_number": 1,
"added_snapshot_id": 2106886542339613321,
"added_files_count": 1,
"existing_files_count": 0,
"deleted_files_count": 0,
"added_rows_count": 500,
"existing_rows_count": 0,
"deleted_rows_count": 0,
"partitions": [],
"key_metadata": null
}
]manifest file을 확인해보면 datafile에 대한 정보와 위치를 확인 할 수 있습니다. "data_file"을 보면 500개의 rows로 추가한 것과 컬럼 별 null/nan value 개수 등도 확인 할 수 있습니다.
[
{
"status": 1,
"snapshot_id": 2106886542339613321,
"data_sequence_number": null,
"file_sequence_number": null,
"data_file": {
"content": 0,
"file_path": "s3a://warehouse/test_ns/test_data/data/00000-0-37dd7d5a-4537-4ddd-b50c-3a1bafcee3cd.parquet",
"file_format": "PARQUET",
"partition": {},
"record_count": 500,
"file_size_in_bytes": 28638952,
"column_sizes": [
{
"key": 1,
"value": 1227
},
{
"key": 2,
"value": 1440
},
{
"key": 3,
"value": 76
},
{
"key": 6,
"value": 102
},
{
"key": 7,
"value": 1002
},
{
"key": 5,
"value": 28632530
}
],
"value_counts": [
{
"key": 1,
"value": 500
},
{
"key": 2,
"value": 500
},
{
"key": 3,
"value": 500
},
{
"key": 6,
"value": 1000
},
{
"key": 7,
"value": 1000
},
{
"key": 5,
"value": 500
}
],
"null_value_counts": [
{
"key": 1,
"value": 0
},
{
"key": 2,
"value": 0
},
{
"key": 3,
"value": 0
},
{
"key": 6,
"value": 0
},
{
"key": 7,
"value": 500
},
{
"key": 5,
"value": 0
}
],
"nan_value_counts": [],
"lower_bounds": [
{
"key": 1,
"value": "+\u0015dl\u0019\u0006\u0000"
},
{
"key": 2,
"value": "\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
},
{
"key": 3,
"value": "u"
}
],
"upper_bounds": [
{
"key": 1,
"value": "7\u0015dl\u0019\u0006\u0000"
},
{
"key": 2,
"value": "\u0001\u0000\u0000\u0000\u0000\u0000\u0000"
},
{
"key": 3,
"value": "u"
}
],
"key_metadata": null,
"split_offsets": [
4
],
"equality_ids": null,
"sort_order_id": null
}
}
]다시 종합하여 보자면 아래의 그림과 같습니다.(COW 기준)
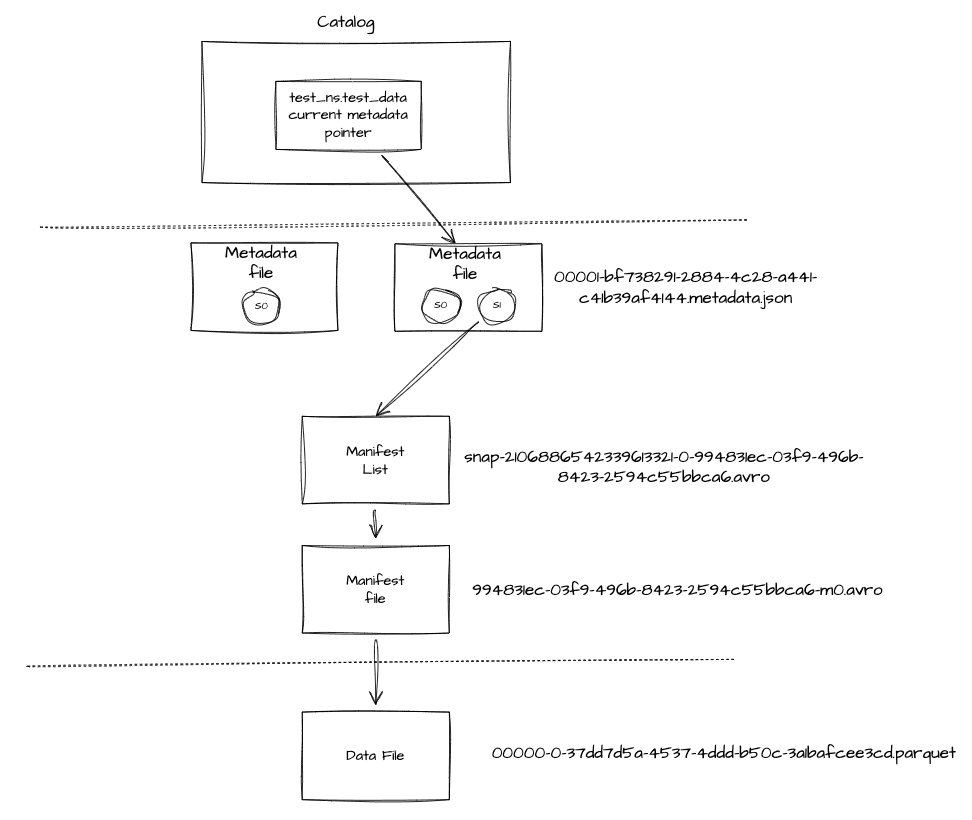
그림에서 보다시피 iceberg 테이블에서 데이터를 읽어올 때 catalog는 최신의 메타데이터 파일을 확인해서 메타데이터 파일에서 현재의 스냅샷 정보를 확인해 manifest List -> Manifest File -> Data File로 내려가 관련된 정보를 획득합니다. manifest list 파일 정보에서 partition 정보가 있습니다. partition 정보에 따라 관련된 manifest 파일들만을 가져와 성능을 향상시킵니다. 또한 Datafile들도 lower_bounds와 upper_bounds 정보를 갖고 있어 이 정보에 따라 관련된 데이터만을 갖고 있는 datafile들만 읽어옵니다.(pruning) 이러한 partition과 upper/lower bound 값, parquet open-file 포멧이 지원하는 기능으로 iceberg는 성능을 향상시킵니다.
* 현재 2024.5월 기준 pyiceberg(0.6.1) 라이브러리는 partition이 적용된 테이블에 write 기능을 제공하지 않고 있어 적용되어 있지 않습니다. 추후 이 기능은 0.7 릴리즈 버전에 적용할 예정으로 되어 있습니다.
Compaction
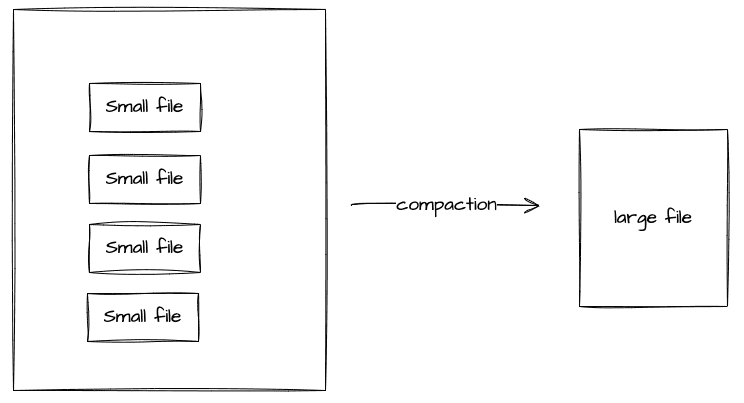 위에서 언급한 것처럼, 여러 작은 파일로 저장된 데이터는 불러올 때 I/O 오버헤드가 발생하는 small files 문제를 야기합니다. 이를 해결하기 위해 레이크하우스는 작은 파일들을 주기적으로 큰 파일로 재작성하는 compaction 기능을 제공합니다. compaction 방법으로는 binPack(기본값), Sort, zOrder, filter, option(s)가 있습니다.
위에서 언급한 것처럼, 여러 작은 파일로 저장된 데이터는 불러올 때 I/O 오버헤드가 발생하는 small files 문제를 야기합니다. 이를 해결하기 위해 레이크하우스는 작은 파일들을 주기적으로 큰 파일로 재작성하는 compaction 기능을 제공합니다. compaction 방법으로는 binPack(기본값), Sort, zOrder, filter, option(s)가 있습니다.
- binPack: 기본 설정으로, 레코드를 정렬하지 않고 파일만 결합합니다. compaction 속도가 빠르지만 관련 데이터가 모여있지 않아 읽기 성능에 영향을 줄 수 있습니다.
- Sort: 원하는 순서대로 필드를 정렬하여 자주 사용하는 필드로 쿼리 시 성능이 향상되지만, compaction 시 binPack에 비해 시간이 오래 걸립니다.
- zOrder: 여러 필드를 동일한 가중치로 정렬하여, 여러 필드로 쿼리할 때 유리합니다. zOrder도 compaction 시 binPack에 비해 시간이 오래 걸립니다.
- filter: 사용자의 데이터 조건에 부합하는 데이터들에 대해 수행합니다.
- option: target-file-size, file-group-size 등 물리적으로 저장되는 파일 크기 등과 같은 옵션들을 설정합니다
compaction 전략은 여러 사용 시나리오에 따라 선택할 수 있습니다. 스트리밍 시 또는 빠른 시간 내에 처리가 필요한 경우에는 binPack을 사용하는 것이 좋습니다.
Copy-on-Write vs Merge-on-Read
속도에 영향을 주는 다른 한 부분은 row-level update 방식입니다. 위에서 간단하게 말한 것과 같이 테이블에 write 시 COW or MOR에 따라 Read / Write 속도에 영향을 줍니다. COW는 최신의 모든 데이터를 새로운 파일에 저장하므로 write는 상대적으로 시간이 오래 소요되지만 Read 시에는 가장 빠릅니다. 반대로 MOR의 경우 write의 경우 상대적으로 시간이 적게 소요되지만 Read는 COW에 비해 느립니다. MOR의 경우 delete files를 따로 관리하게 되는데 삭제한 파일들에 대한 기록을 담습니다. 이에 따라 Position Delete와 Equality Delete의 방식으로 나뉘게 됩니다. 심플하게 얘기하면 Position Delete는 데이터의 위치를 관리하여 이를 이용하여 삭제하며 Equlity Delete는 값 자체를 참조하여 삭제합니다. 여기서는 Delete 방식은 더 깊게 살펴보지는 않겠습니다.
Concurrent Write
iceberg는 데이터를 write 할 때 여러 프로세스 혹은 여러 노드가 동시다발적으로 파일을 쓸 수 있도록 기능을 제공합니다. 메타데이터를 생성할 시에 atomic한 swapping을 수행하며 atomic swapping이 실패할 시 retry하여 새로운 메타데이터를 생성합니다
Object Storage
objcet storage를 스토리지로 사용할 경우 multipart-upload를 사용하여 데이터 upload 성능을 향상합니다
속도 비교
기존의 데이터를 로드하는 방식(메타데이터(RDB) + 원시 데이터(object storage))과 iceberg table 사용했을때의 데이터 로드 속도를 아래의 환경에서 single-thread, multi-processing, iceberg로 사용했을때를 비교해 보았습니다.
- 서버 10 cpu, 256GB RAM, 10G Network
Single Thread vs Multi Processing(Ray) vs Iceberg
-
약 20,000개의 파일 기준 17분 18초(single thread) / 3분 22초(ray multi-processing) / 2분 28초(pyiceberg) 소요
-
ray framework는 python 자체에서 제공해주는 multi-processing보다 월등한 성능을 제공하는데 원프레딕트 내부에서 사용하고 있어 실제적인 사용 시나리오에 맞추기 위해 ray를 사용하였습니다.
-
내부에서 사용하고 있는 데이터로드는 코드를 명시하지 않았습니다(dl instance)
-
Single thread(17분 18초)
import time
objects = []
start = time.time()
for r in rows:
objects.append(dl.load(site=r["site"], process=r["process"], file_path=r["file_path"]))
print(f"elapsed: {(time.time() - start) / 60}m")
- Ray Multi Processing(3분 22초)
import ray
import time
@ray.remote
def get_object(r):
return dl.load(site=r["site"], process=r["process"], file_path=r["file_path"])
start = time.time()
tasks = [get_object.remote(r) for r in rows]
objects = ray.get(tasks)
print(f"elapsed: {(time.time() - start) / 60}m")- pyiceberg(2분 28초)
import pendulum
import time
from pyiceberg.catalog import load_catalog
catalog = load_catalog('catalog', **{
'uri': 'http://rest-catalog:8181',
's3.endpoint': 'http://minio:9000',
's3.access-key-id': 'test',
's3.secret-access-key': 'test',
})
start_time="2023-08-01"
end_time="2023-09-01"
start = time.time()
pa_table = tbl.scan(row_filter=f"acq_time >= '{pendulum.parse(start_time).isoformat()}' and \
acq_time <= '{pendulum.parse(end_time).isoformat()}' ").to_arrow()
print(f"elapsed: {(time.time() - start) / 60}m")테스트 환경 구성
- 위의 내용들을 위해 간단하게 minio를 스토리지로하여 rest-catalog를 사용하고 데이터 엔진으로 pyiceberg를 사용하여 테스트 환경을 구성해보았습니다.
Rest Catalog & Object Storage(Minio) Set up
Docker Compose(yml)
version: "3"
services:
rest-catalog:
image: tabulario/iceberg-rest
ports:
- 8181:8181
environment:
- AWS_ACCESS_KEY_ID=test
- AWS_SECRET_ACCESS_KEY=test
- AWS_REGION=us-east-1
- CATALOG_WAREHOUSE=s3a://warehouse
- CATALOG_IO__IMPL=org.apache.iceberg.aws.s3.S3FileIO
- CATALOG_S3_ENDPOINT=http://minio:9000
- CATALOG_S3_PATH__STYLE__ACCESS=true
minio:
image: minio/minio
ports:
- "9000:9000"
- "9001:9001"
volumes:
- minio_storage:/data
environment:
MINIO_ROOT_USER: test
MINIO_ROOT_PASSWORD: test
command: server --console-address ":9001" /data
- tabular에서 제공하는 rest catalog는 apache iceberg의 jdbc catalog를 wrapping 하는 형태로 되어 있으며 rest api로 엔드포인트를 제공하게 되어 있습니다. jdbc catalog에 옵션을 적용하기 위해서 CATALOG_접두어를 가진 환경변수로 설정을 적용할 수 있습니다.
- CATALOG_S3_PATH__STYLE__ACCESS의 옵션의 경우 s3_endpoint를 DNS(http://minio) 를 사용하여 접근할 수 있게 해줍니다.
Python libray install
pip install pyiceberg pyarrow pandasLoad catalog
from pyiceberg.catalog import load_catalog
catalog = load_catalog('catalog', **{
'uri': 'http://rest-catalog:8181',
's3.endpoint': 'http://minio:9000',
's3.access-key-id': 'test',
's3.secret-access-key': 'test',
})Create namespace & iceberg table
test_ns = "test_ns"
test_table = "test_data"
pa_schema = pa.schema([
("date_time", pa.timestamp(unit="us", tz="UTC")),
("int_data", pa.int64()),
("str_data", pa.string()),
("map_data", pa.map_(pa.string(), pa.string())),
("binary_data", pa.large_binary())
])
catalog.create_namespace(test_ns)
catalog.create_table(identifier=(test_ns, test_table), schema=pa_schema)
Insert test data
import pendulum
import pyarrow as pa
import numpy as np
nums = 500
test_data = {
"date_time": [pendulum.now() for _ in range(nums)],
"int_data": [i for i in range(nums)],
"str_data": ["u" for _ in range(nums)],
"map_data": [{"a": f"a_{i}", "b": None } for i in range(nums)],
"binary_data": [np.random.rand(16000).astype(np.float32).tobytes() for _ in range(nums)]
}
pa_table = pa.Table.from_pydict(test_data, schema=pa_schema)
tbl.append(pa_table)
Load data from iceberg table
tbl = catalog.load_table((test_ns, test_table))
df = tbl.scan().to_pandas()
len(df)여기까지 레이크하우스에 대해 그 중에서 원프레딕트에서 사용하고 있는 Iceberg에 대해 데이터 로드 관련되어 알아보는 시간이었습니다.
Lakehouse(Iceberg)를 사용해보며 느낀점
배치 데이터 형태로 데이터를 로드할 시에 속도 향상에 매우 긍정적인 효과가 있었습니다. 하지만 데이터가 증가함에 따라 쿼리 계획에서 시간 소요가 증가하게 되며 적은 데이터양을 불러올 때는 오히려 쿼리 계획에서 시간이 더 오래 걸리기도 하였으며 sort, partition, compaction을 통해 주기적으로 repartition / rewrite 등에 대해 최적화 전략이 중요하다고 느꼈습니다. 또한 iceberg는 실제로 데이터를 삭제하지 않고 추가를 하다 보니 스토리지 저장소 공간이 매우 빠르게 증가하였습니다. 여기 블로그에는 따로 기재하지는 않았지만, Iceberg가 지원하는 Expire Snapshots / Remove old metadata files / Delete orphan files과 같은 기능들을 상황에 맞는 정책을 설정하여 운영이 필요함을 느꼈습니다.
앞으로 해야할 일
지금까지 단순히 Read/Write 기능을 사용하는 수준으로만 그쳤다면 여러 가지 Usecase에 따라 데이터를 어떻게 저장하고 사용자들에게 필요한 데이터를 식별하여 사용하게 할 것인가에 대한 데이터 디스커버리와 데이터 플랫폼을 운영하기 위한 거버넌스 측면에 대한 고려가 필요합니다. 이 부분에 대해서는 원프레딕트에서 사용하고 있는 방안을 다음에 블로그를 통해 소개해 드리도록 하겠습니다.
MLOps 팀에서는 저희와 함께 MLOps 플랫폼, 데이터 플랫폼을 개발하실 분들을 찾고 있습니다. 관심이 있으시다면 언제든지 연락해 주세요. 꼭 입사 지원이 아니더라도 커피 챗 등을 통해 ML 프로세스를 지원하는 플랫폼 개발에 관해 이야기 나누는 것도 좋습니다.