




글 목록
- 데이터 플랫폼 구축기 Part 1 - Lakehouse 기반 데이터 플랫폼 소개
- 데이터 플랫폼 구축기 Part 2 - 필요한 기능이 없으면 기여하면 되지 않을까요?
- 데이터 플랫폼 구축기 Part 3 - Lakehouse 사용기
배경
1편에서 소개한 데이터 플랫폼의 아키텍처를 다시 한 번 살펴보겠습니다.
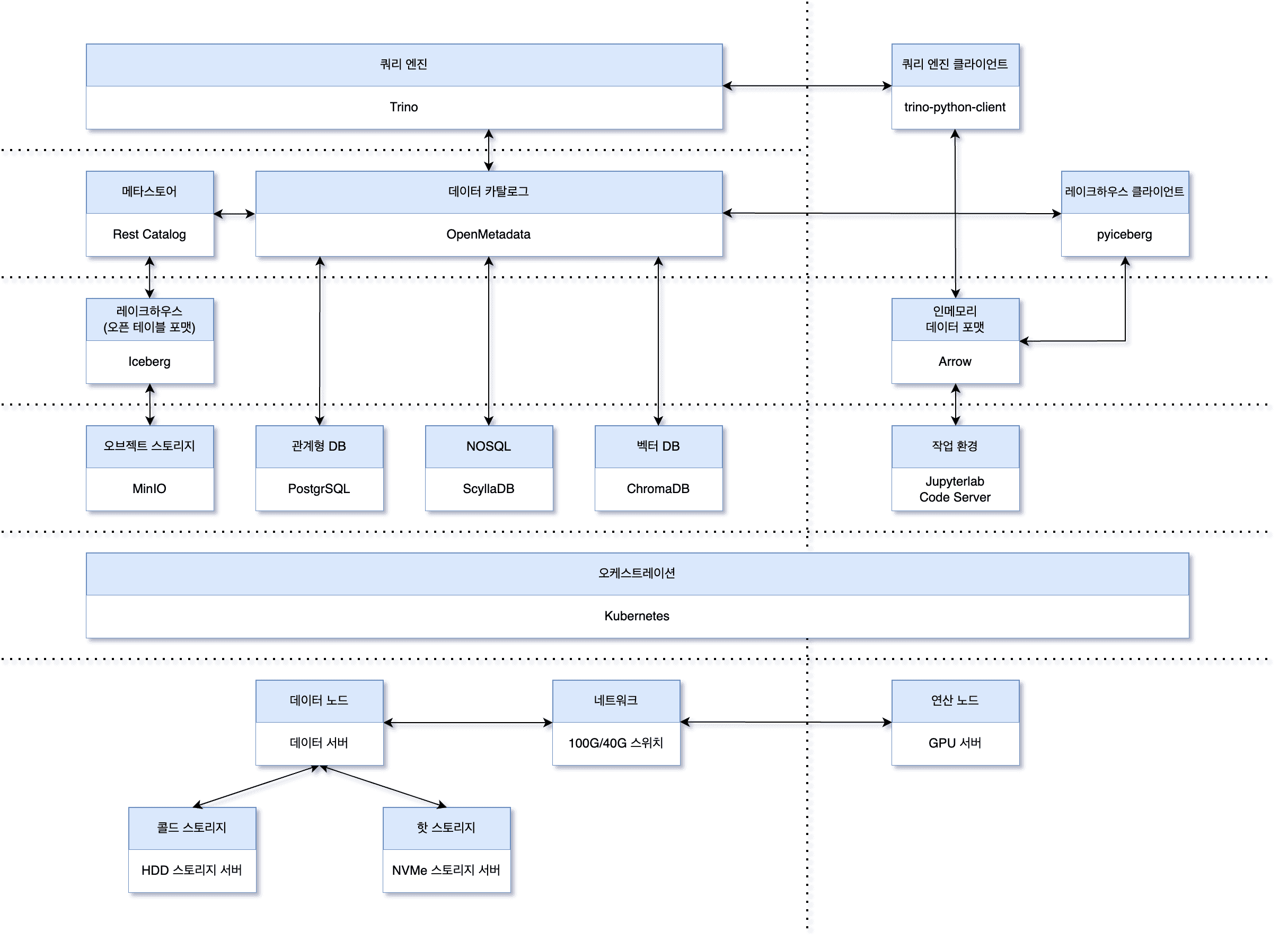
아키텍처의 핵심은 iceberg를 활용하여 데이터 레이크하우스 기반의 데이터 플랫폼을 구축하는 것입니다. 저희는 파이썬을 주 언어로 사용하고 있기 때문에, iceberg에 접근하기 위해 pyiceberg 라이브러리를 사용하고 데이터를 불러온 뒤에는 Arrow 기반의 라이브러리를 활용하고 있습니다.
발견한 문제
저희가 주로 사용하는 데이터는 Multi Channel Long Array의 형태입니다. 가디원 모터의 예를 들면 u,v,w의 3상을 5분 간격으로 20초 동안 8000HZ로 데이터를 계측합니다. FFT와 같은 신호처리 기법을 사용할 때는 20초 데이터를 한 번에 처리해야 합니다. 따라서 채널 별로 개별 컬럼을 생성하는 것이 아니라 Array 전체를 바이너리로 저장하는 것이 효율적입니다.
이를 반영한 iceberg의 스키마는 다음과 같습니다.
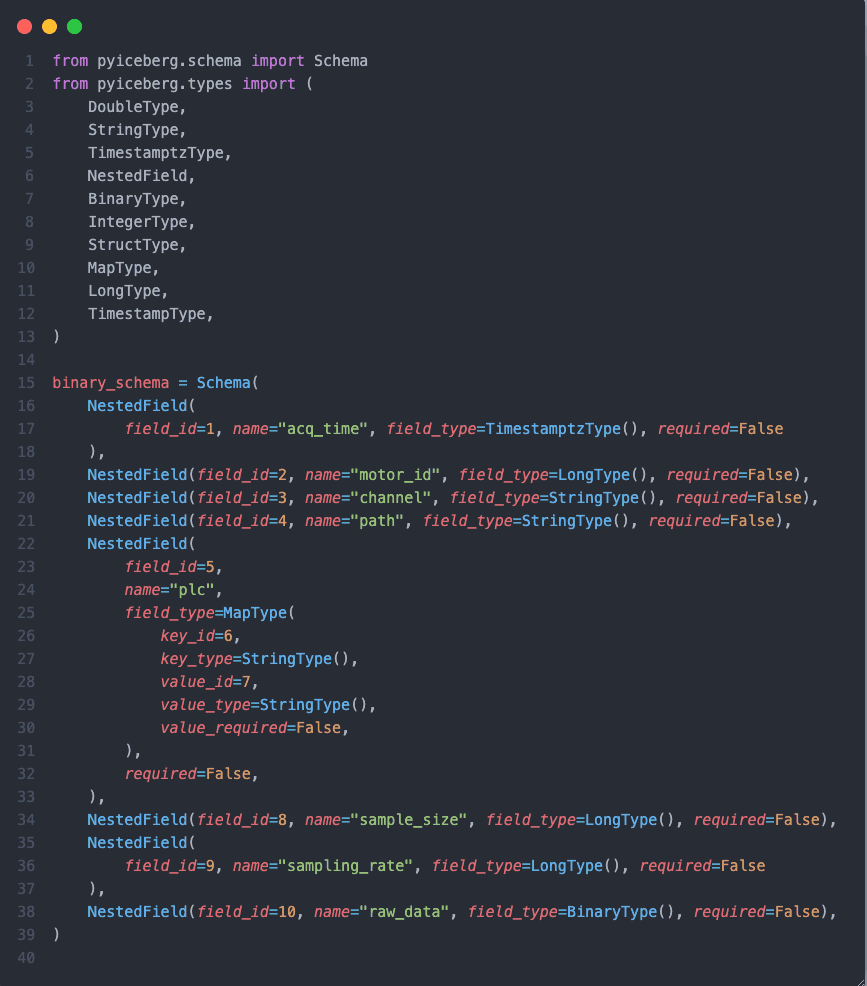
계측 시간, 설비 정보, 채널 정보와 같은 메타 정보와 함께 raw_data 필드에 원시 신호를 가지고 있습니다.
pyarrow의 스키마는 다음과 같이 정의하였습니다.
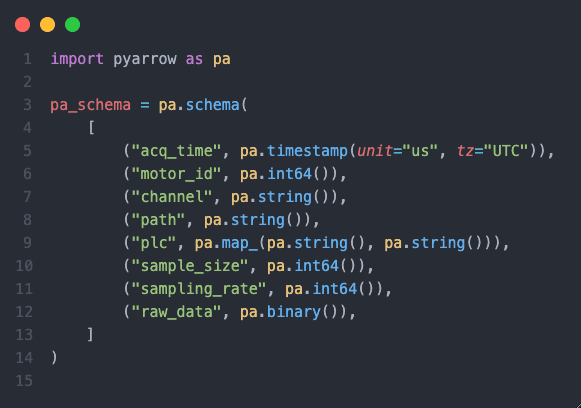
raw_data 필드는 문서에서 안내한 대로 pa.binary()로 정의하였습니다.
pyiceberg를 통해 데이터를 불러오는 코드는 다음과 같습니다.
![]()
4000개 정도의 row를 저장한 뒤에 데이터를 불러와보니 다음과 같은 에러가 발생했습니다.
ArrowInvalid: offset overflow while concatenating arrays검색을 해보니 pyarrow를 데이터 프레임 처리 엔진으로 사용하는 라이브러리에서 종종 발생하는 문제였습니다.
arrow의 binary는 기본적으로 32비트로 처리되기 때문에 2GB 이상의 데이터를 처리할 때 발생하는 문제였습니다. 저희가 다루는 데이터는 2GB를 한참 넘기 때문에 이 문제를 해결해야 했습니다.
포크냐 기여냐
처음에는 pyiceberg를 사내 pypi 리포지토리에 포크를 한 뒤 필요한 부분만 수정을 할까 고민했습니다. 하지만 pyiceberg는 아직 초기 단계이기 때문에 앞으로 추가될 기능이 많을 것이고, 저희가 포크를 해서 사용하더라도 pyiceberg의 버전이 높아질 때마다 이러한 변경을 계속 추가해야 할 것이라고 생각했습니다. 그래서 시간을 더 투입하더라도 pyiceberg에 기여하기로 결정했습니다. 해당 오픈 소스의 관리자가 원하는 방향이 맞는지부터 확인하기 위해 pyiceberg에 이슈를 올렸습니다.
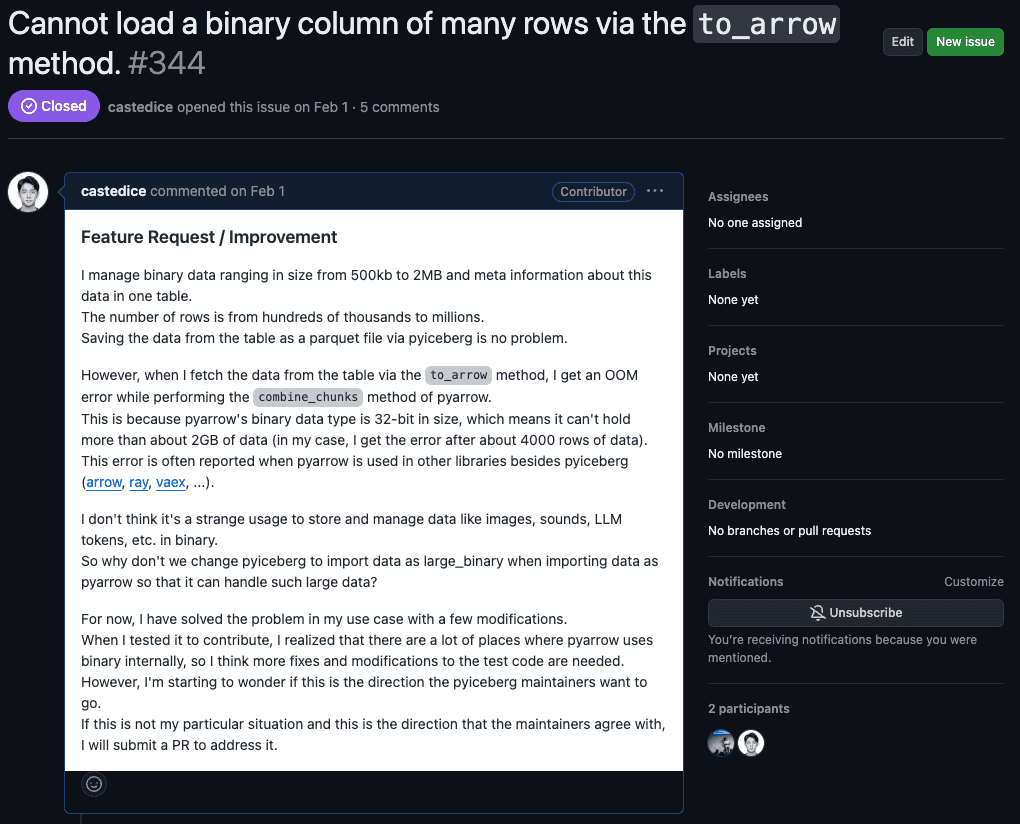
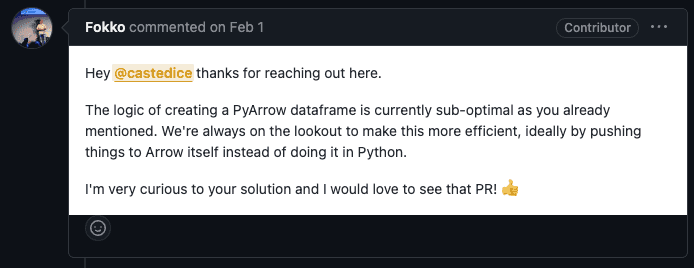
15분도 안 돼서 관리자에게 피드백이 왔고 해결 방법이 무엇일지 궁금해하는 반응이었습니다.
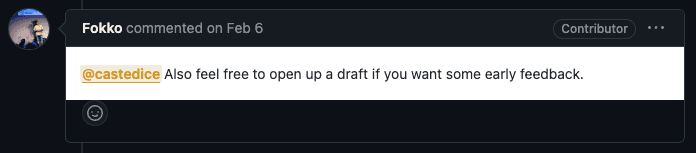
바빴던 주라 작업이 조금 늦춰졌는데, 언제든 빠른 피드백을 해줄 테니 초안을 올려보라는 답변을 받았습니다.
(관심을 가져줘서 좋았지만 부담도 되었습니다.)
기여 과정
기여를 하기 위한 준비
기여를 시작하기 전에 관련된 문서를 찾아보았습니다.
여느 오픈 소스 프로젝트와 크게 다른 점은 없었습니다.
저는 다음과 같은 계획을 세웠습니다.
- pyiceberg를 포크 합니다.
- 새로운 브랜치를 생성합니다.
- 개발 환경을 세팅합니다.
- 문제 상황을 재현하는 테스트 코드를 작성합니다.
- 코드를 작성합니다.
- 린트와 테스트를 수행합니다.
- 작성한 코드를 커밋하고 푸시 합니다.
- 원래의 리포지토리에 PR을 올립니다.
개발 환경을 세팅하는 과정은 생각보다 쉽지 않았습니다. 특히 애를 먹었던 부분은 Cython으로 빌드 되는 모듈이 있었는데 계속해서 빌드가 제대로 되지 않아 패키지 설치에 문제가 발생했습니다. 에러가 명확하게 나오지 않아 원인을 찾는데 시간이 오래 걸렸습니다. 원인은 Cython 빌드를 위한 경로가 제대로 설정되지 않아 발생한 문제였습니다.
라이브러리 코드 파악
카탈로그에서 불러온 테이블 객체에서 to_arrow() 메서드를 통해 pyarrow 객체로 만드는 과정은 다음과 같습니다.
to_arrow()메서드에서project_table()메서드를 호출합니다.project_table()메서드는 쿼리 조건에 맞는 행과 열을 선택한 뒤, 각 열을 pyarrow 타입에 맞추어 변경해서 새로운 테이블을 생성합니다. 행과 열을 선택하는 과정은 방문자 패턴을 사용합니다.bind()메서드와schema_to_pyarrow()메서드를 확인해 보세요.- pyarrow 스키마의 타입을 적용하는 과정은
_ConvertToArrowSchema의 메서드들을 통해 이루어집니다. - 바이너리 타입은
visit_binary()메서드에서 처리되게 됩니다.
변경 사항
여기까지 파악하고 나면 사실상 구현은 끝났습니다.
- iceberg의 바이너리 타입이 처리될 때 2GB 이상의 데이터를 처리할 수 있도록
pa.binary()대신pa.large_binary()을 사용하도록 수정합니다. - pyarrow의
pa.binary()뿐만 아니라pa.large_bianry()도 pyiceberg의BinaryType으로 매핑 되도록 수정합니다.
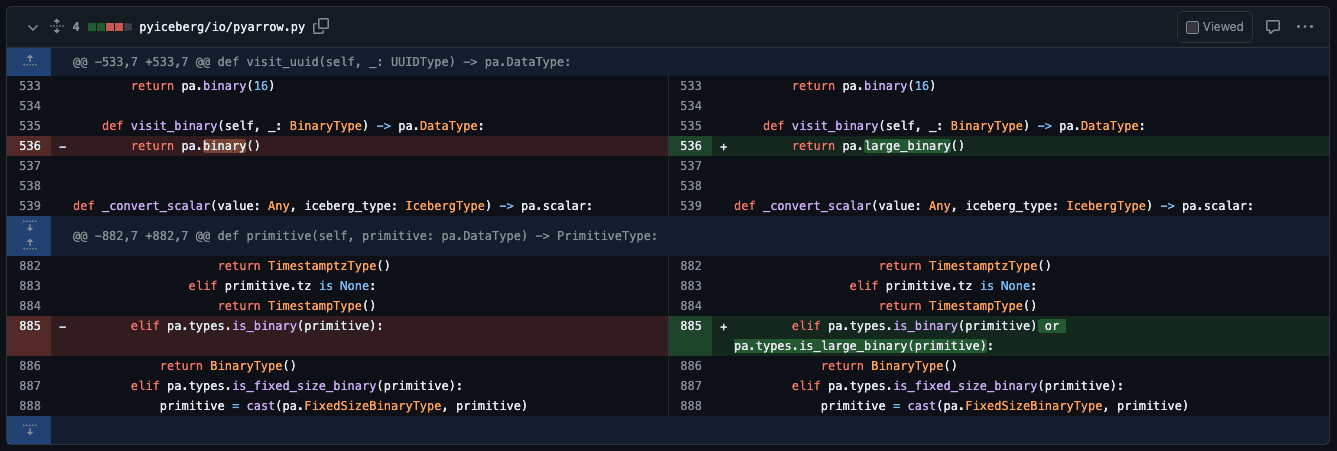
테스트 코드가 변경된 코드에서도 잘 작동하는지 확인하고, 필요한 경우에는 테스트 코드를 수정하였습니다.
소감
사실 이번 기여는 크게 어렵지 않았습니다. 아직 프로젝트 초창기이기 때문에 코드 베이스를 이해하는 것도 어렵지 않았고, 제가 원하는 기능이 아주 작은 부분이었기 때문에 수월하게 진행할 수 있었습니다. 얼마 지나지 않아 pyiceberg 0.6.0 버전이 릴리즈 되면서 제가 추가한 기능이 생각보다 빠르게 추가되어 데이터 플랫폼에 빠르게 적용할 수 있었습니다. 이러한 작은 기여를 통해 오픈 소스 생태계를 활성화시키고 데이터 플랫폼 아키텍처를 구상했던 그대로 구현할 수 있는 점이 매우 만족스러웠습니다.
앞으로 해야할 일
데이터를 조회하는 부분은 이번 기여를 통해 해결되었지만, 데이터를 쓰는 부분에서는 아직도 문제가 남아 있습니다. 데이터를 저장하는 기능이 이번 0.6.0 버전에 함께 추가된 기능이기 때문에 당시에는 확인할 수 없었습니다. 조만간 데이터를 저장하는 부분에도 대용량 데이터를 처리할 수 있도록 또 다른 기여를 할 예정입니다.
MLOps 팀에서는 저희와 함께 MLOps 플랫폼, 데이터 플랫폼을 개발하실 분들을 찾고 있습니다. 관심이 있으시다면 언제든지 연락해 주세요. 꼭 입사 지원이 아니더라도 커피 챗 등을 통해 ML 프로세스를 지원하는 플랫폼 개발에 대해 이야기 나누는 것도 좋습니다.