




Intro
지난주 아별님께서 작성한 Kafka Message Delivery Semantics글에서 Producer의 ack 설정에 따른 Producer-Broker 동작 방식에 대해서 알아보았습니다. 아별님 글에서 언급되었듯이, Producer를 통하여 생산된 데이터는 Broker 내부의 Partition에 저장됩니다. 이 때, 단일 partition 환경으로 kafka가 구축되어 있다면 rabbitmq처럼 FIFO(First In First Out) 형태로 메시지를 consume 할 수 있습니다. 그러나 kafka는 다수의 파티션을 구성 할 수 있으며, 이에 따라서 여러 가지 전략을 취할 수 있습니다.
이 글 시리즈에서는 다수의 파티션 환경에서의 데이터 플로우를 이해하고, 상황에 맞는 전략을 세울 수 있는 것이 목표입니다.
Producer 구성요소 및 동작 방식
각 구성요소 및 성능에 영향을 미치는 configuration은 아랫글을 참조합니다.
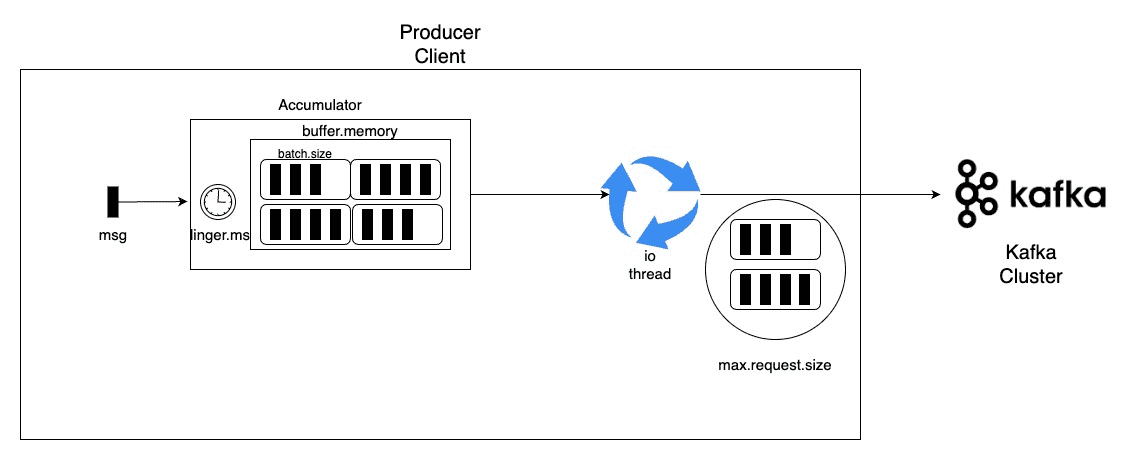
Accumulator
Kafka Cluster로 전송할 kafka record를 임시로 memory에 담고 있습니다. 담을 때 적용되는 주요 kafka producer configuration은 아래와 같습니다.
Network Thread (io_loop)
Accumulator에 쌓인 record를 Broker로 전송하는 역할을 합니다.
Producer 성능에 직접적으로 영향을 주는 configuration
-
buffer.memory : kafka producer가 메시지를 보내기 전 메모리에 보관하는 전체 메시지 용량을 의미합니다. (Default : 32MB)
-
max.request.size : 단일 요청으로 보낼 수 있는 최대 메시지의 크기를 의미합니다. (default : 1MB)
-
batch.size : 단일 배치 요청으로 단일 파티션에 요청을 보낼 수 있는 메시지들의 크기의 최대 합을 의미합니다.
-
linger.ms : producer가 batch.size에 도달하기까지 기다릴 수 있는 시간입니다.
하나의 request가 만들어지는 절차
-
message가 발행된다.
-
message들의 합이 batch.size가 될 떄 까지 기다린다.
-
linger.ms보다 먼저 batch.size를 넘어 설 경우, batch.size 크기로 batch를 묶는다.
-
linger.ms에 먼저 도달할 경우, 도달 전까지의 데이터만 batch 단위로 묶는다.
-
-
max.request.size보다 message 크기가 작은 경우만 전송이 완료된다.
Producer Partitioning에 따른 데이터 적재 방식
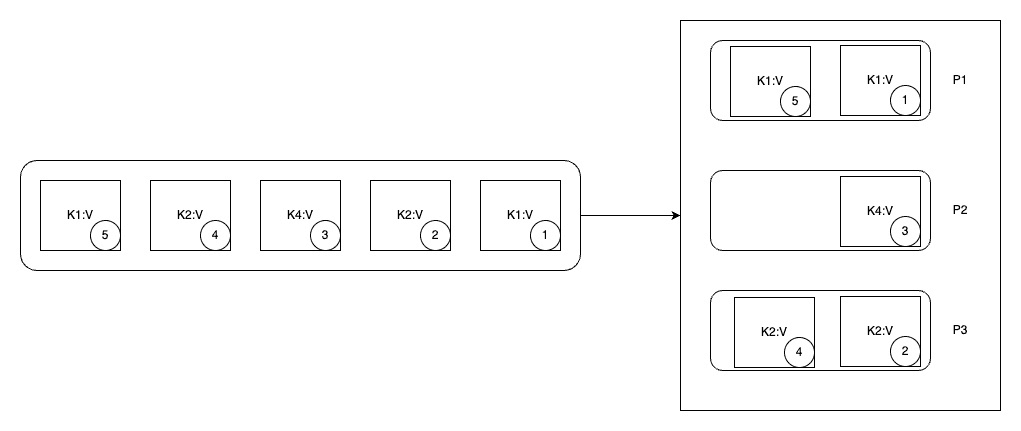
Partitioning key가 있을 때
key가 있을 경우, 키를 murmur2 알고리즘을 이용하여 해쉬화 하여 partition 번호로 변환합니다. 이 번호를 기준으로 각 메시지는 파티션에 적재가 됩니다.
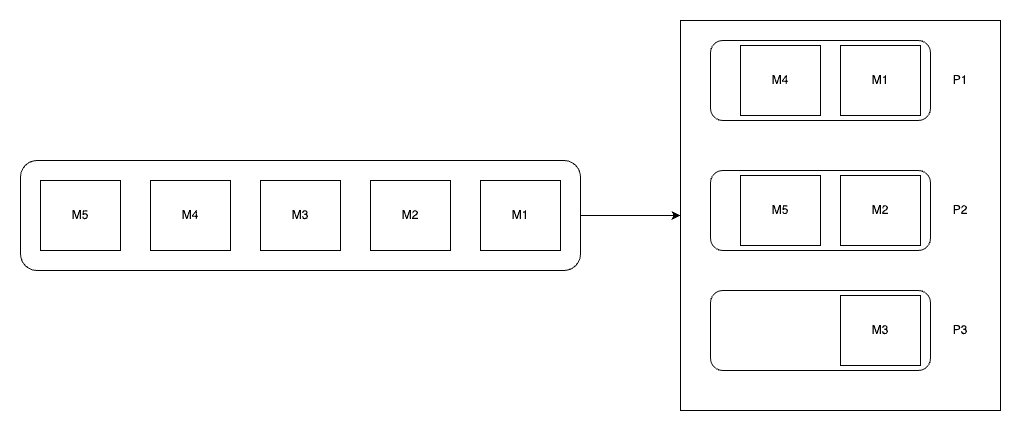
Partitioning key가 없으며, kafka version이 2.4 미만일 경우
이 경우, 전략이 명시되지 않으면 round robin partitioning 전략이 자동으로 채택됩니다. 따라서 순차적으로 파티션 순서대로 돌아가면서 메시지가 적재됩니다. 중간에 busy한 partition을 만나게 되면 해당 partition은 건너뛸 수 있습니다.
Partitioning key가 없으며, kafka version이 2.4 이상인 경우
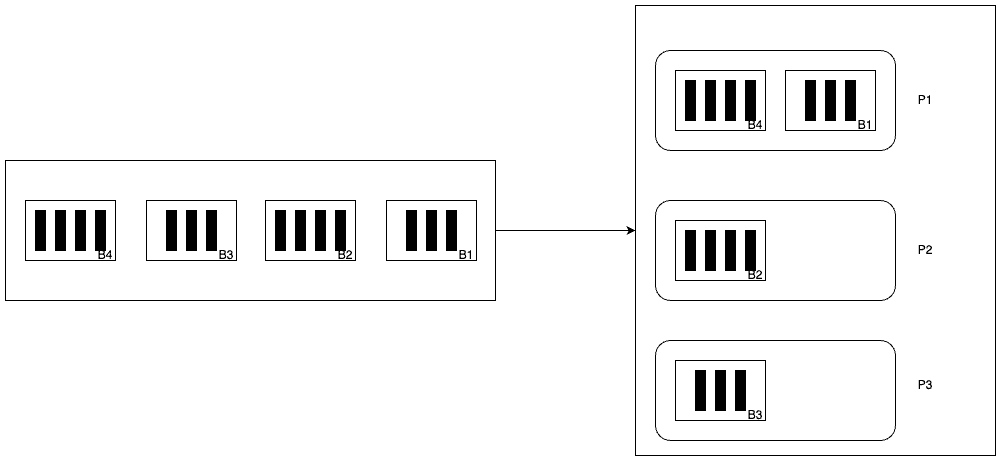 2.4 미만의 버전보다 배치 프로세싱에 성능 개선을 둔 방식입니다. 위 producer configuration에서 설명한 요소 중 batch.size, linger.ms를 이용하여 하나의 파티션에 최대한 같은 단위로 묶어 하나의 파티션에 적재하는 방법입니다. 이 방법은 sticky partitioning이라고 불립니다.
2.4 미만의 버전보다 배치 프로세싱에 성능 개선을 둔 방식입니다. 위 producer configuration에서 설명한 요소 중 batch.size, linger.ms를 이용하여 하나의 파티션에 최대한 같은 단위로 묶어 하나의 파티션에 적재하는 방법입니다. 이 방법은 sticky partitioning이라고 불립니다.
-
linger.ms에 도달하기 전 batch.size를 만족시키는 모든 message들은 같은 파티션에 적재됩니다.
-
batch.size보다 message들의 크기가 작지만, linger.ms를 넘어서기 직전까지의 모든 message들은 같은 파티션에 적재가 됩니다.
마치며
Kafka producer에서의 주요 설정 값들에 의해서 어떤 방식으로 데이터가 broker에 흘러가고 적재되는지에 대해 알아보았습니다. 순서보장이 필요하거나 특정 단위로 처리해야 할 상황에는 sticky partitioning 전략을 통해 준 실시간 처리를 구성할 수 있으며, 순서나 배치 처리가 필요 없는 경우에는 단순 round robin을 채택하여도 무방 할 것으로 보입니다.
Kafka를 이용하여 실시간 데이터를 다뤄보고 싶은 분 께서는 Onepredict에 합류하여 함께 데이터 엔지니어링을 즐기면 좋겠습니다!